在规划社会调查项目时,要是单纯依靠传统文本规划,很容易出现逻辑不清晰、细节被遗漏的问题。而思维导图作为一种可视化、结构化的工具,可以高效整合调查目的、调查对象以及数据分析等核心模块内容。对调查员来说,思维导图的作用远不止提升效率,它还能让工作变得有条不紊,避免手忙脚乱。
接下来,咱们以“图形天下思维导图”工具为例,结合社会调查项目策划,看看它是如何梳理逻辑、整合资源,让项目规划更科学、执行更高效的。
1. 调查目的层级化拆解
社会调查开展前,得先弄清楚“为何要调查”以及“想要解决什么问题”。但用文本描述时,常常会出现逻辑链条断裂的情况,进而导致调查目标偏离。而借助图形天下思维导图,调查员能够迅速搭建起“总目标 - 子目标 - 评估指标”这样的多层架构。
比如,在“老年人数字鸿沟”调查中,一级分支是“分析技术应用障碍”,可将其拆解为“设备使用频率”、“技能培训需求”、“心理接受度”等子节点,并用不同颜色标注优先级。这种分层展示既能保证目标全覆盖,又能通过显示层级功能聚焦关键指标,避免规划阶段信息过载。
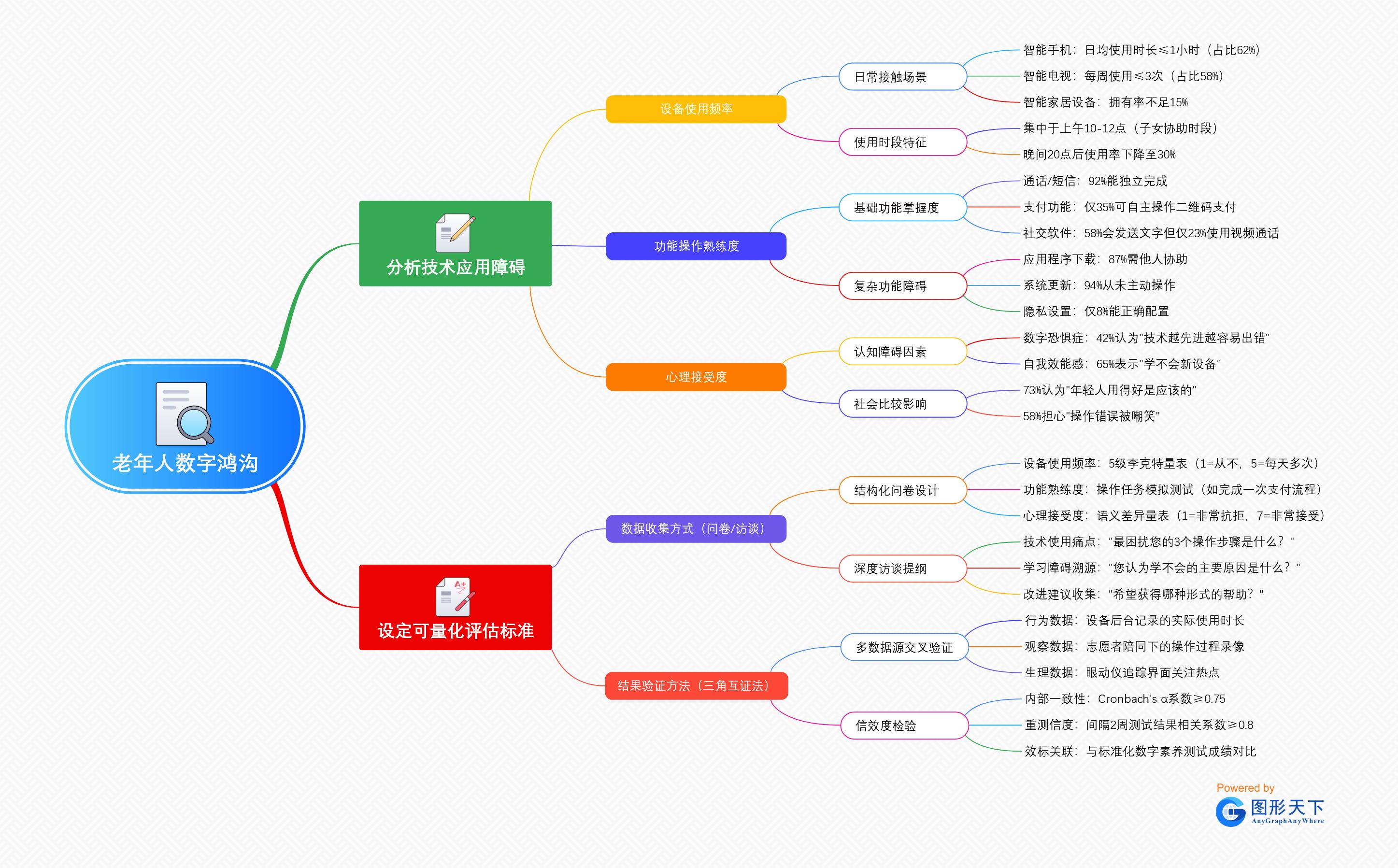
- 老年人数字鸿沟
- 分析技术应用障碍
- 设备使用频率
- 日常接触场景
- 智能手机:日均使用时长≤1小时(占比62%)
- 智能电视:每周使用≤3次(占比58%)
- 智能家居设备:拥有率不足15%
- 使用时段特征
- 集中于上午10-12点(子女协助时段)
- 晚间20点后使用率下降至30%
- 日常接触场景
- 功能操作熟练度
- 基础功能掌握度
- 通话/短信:92%能独立完成
- 支付功能:仅35%可自主操作二维码支付
- 社交软件:58%会发送文字但仅23%使用视频通话
- 复杂功能障碍
- 应用程序下载:87%需他人协助
- 系统更新:94%从未主动操作
- 隐私设置:仅8%能正确配置
- 基础功能掌握度
- 心理接受度
- 认知障碍因素
- 数字恐惧症:42%认为"技术越先进越容易出错"
- 自我效能感:65%表示"学不会新设备"
- 社会比较影响
- 73%认为"年轻人用得好是应该的"
- 58%担心"操作错误被嘲笑"
- 认知障碍因素
- 设备使用频率
- 设定可量化评估标准
- 数据收集方式(问卷/访谈)
- 结构化问卷设计
- 设备使用频率:5级李克特量表(1=从不,5=每天多次)
- 功能熟练度:操作任务模拟测试(如完成一次支付流程)
- 心理接受度:语义差异量表(1=非常抗拒,7=非常接受)
- 深度访谈提纲
- 技术使用痛点:“最困扰您的3个操作步骤是什么?”
- 学习障碍溯源:“您认为学不会的主要原因是什么?”
- 改进建议收集:“希望获得哪种形式的帮助?”
- 结构化问卷设计
- 结果验证方法(三角互证法)
- 多数据源交叉验证
- 行为数据:设备后台记录的实际使用时长
- 观察数据:志愿者陪同下的操作过程录像
- 生理数据:眼动仪追踪界面关注热点
- 信效度检验
- 内部一致性:Cronbach’s α系数≥0.75
- 重测信度:间隔2周测试结果相关系数≥0.8
- 效标关联:与标准化数字素养测试成绩对比
- 多数据源交叉验证
- 数据收集方式(问卷/访谈)
- 分析技术应用障碍
2. 调查对象的精准分类
复杂的社会调查往往会涉及多种不同类型的群体。要是采用传统列表式的方法来罗列调查对象,很难体现出各个群体之间的关联性。而图形天下思维导图提供了海量高质量社区模板,这为我们进行调查对象分类提供了极大的便利。
比如,在开展“新就业形态劳动者权益”调查时,我们可以直接调用相关的模板。通过拖拽节点的方式,能够快速地将外卖骑手、网约车司机、自媒体从业者等不同群体进行分类,从而实现对调查对象的精准划分。
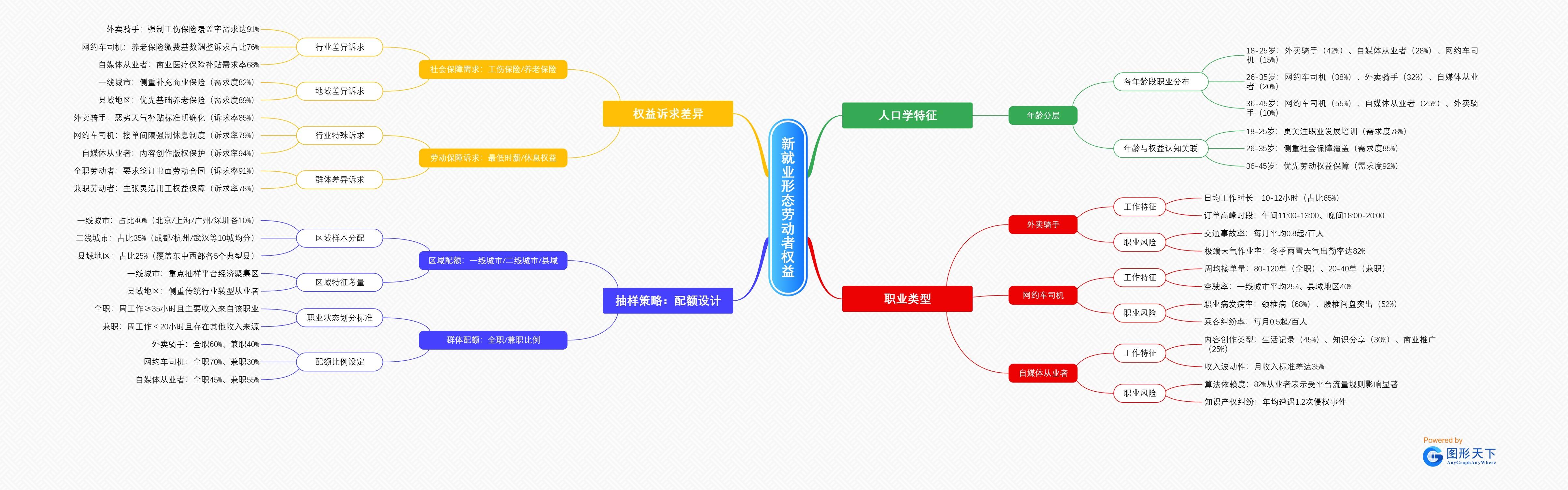
- 新就业形态劳动者权益
- 人口学特征
- 年龄分层
- 各年龄段职业分布
- 18-25岁:外卖骑手(42%)、自媒体从业者(28%)、网约车司机(15%)
- 26-35岁:网约车司机(38%)、外卖骑手(32%)、自媒体从业者(20%)
- 36-45岁:网约车司机(55%)、自媒体从业者(25%)、外卖骑手(10%)
- 年龄与权益认知关联
- 18-25岁:更关注职业发展培训(需求度78%)
- 26-35岁:侧重社会保障覆盖(需求度85%)
- 36-45岁:优先劳动权益保障(需求度92%)
- 各年龄段职业分布
- 年龄分层
- 职业类型
- 外卖骑手
- 工作特征
- 日均工作时长:10-12小时(占比65%)
- 订单高峰时段:午间11:00-13:00、晚间18:00-20:00
- 职业风险
- 交通事故率:每月平均0.8起/百人
- 极端天气作业率:冬季雨雪天气出勤率达82%
- 工作特征
- 网约车司机
- 工作特征
- 周均接单量:80-120单(全职)、20-40单(兼职)
- 空驶率:一线城市平均25%、县域地区40%
- 职业风险
- 职业病发病率:颈椎病(68%)、腰椎间盘突出(52%)
- 乘客纠纷率:每月0.5起/百人
- 工作特征
- 自媒体从业者
- 工作特征
- 内容创作类型:生活记录(45%)、知识分享(30%)、商业推广(25%)
- 收入波动性:月收入标准差达35%
- 职业风险
- 算法依赖度:82%从业者表示受平台流量规则影响显著
- 知识产权纠纷:年均遭遇1.2次侵权事件
- 工作特征
- 外卖骑手
- 权益诉求差异
- 社会保障需求:工伤保险/养老保险
- 行业差异诉求
- 外卖骑手:强制工伤保险覆盖率需求达91%
- 网约车司机:养老保险缴费基数调整诉求占比76%
- 自媒体从业者:商业医疗保险补贴需求率68%
- 地域差异诉求
- 一线城市:侧重补充商业保险(需求度82%)
- 县域地区:优先基础养老保险(需求度89%)
- 行业差异诉求
- 劳动保障诉求:最低时薪/休息权益
- 行业特殊诉求
- 外卖骑手:恶劣天气补贴标准明确化(诉求率85%)
- 网约车司机:接单间隔强制休息制度(诉求率79%)
- 自媒体从业者:内容创作版权保护(诉求率94%)
- 群体差异诉求
- 全职劳动者:要求签订书面劳动合同(诉求率91%)
- 兼职劳动者:主张灵活用工权益保障(诉求率78%)
- 行业特殊诉求
- 社会保障需求:工伤保险/养老保险
- 抽样策略:配额设计
- 区域配额:一线城市/二线城市/县域
- 区域样本分配
- 一线城市:占比40%(北京/上海/广州/深圳各10%)
- 二线城市:占比35%(成都/杭州/武汉等10城均分)
- 县域地区:占比25%(覆盖东中西部各5个典型县)
- 区域特征考量
- 一线城市:重点抽样平台经济聚集区
- 县域地区:侧重传统行业转型从业者
- 区域样本分配
- 群体配额:全职/兼职比例
- 职业状态划分标准
- 全职:周工作≥35小时且主要收入来自该职业
- 兼职:周工作<20小时且存在其他收入来源
- 配额比例设定
- 外卖骑手:全职60%、兼职40%
- 网约车司机:全职70%、兼职30%
- 自媒体从业者:全职45%、兼职55%
- 职业状态划分标准
- 区域配额:一线城市/二线城市/县域
- 人口学特征
3. 数据整理与分析的预处理
原始数据堆积如山,容易导致分析阶段返工。而思维导图能在规划阶段就帮我们预设好分析路径,起到未雨绸缪的作用。借助图形天下思维导图,我们可以把“数据清洗规则”“分析维度映射”“模型预设”等分析要素以可视化的形式呈现出来,这样后续阅读和分析数据时就会更加清晰、便捷。
此外,该工具的“一键播放”功能,能无缝将思维导图转换为内容演示文稿,直接支持流畅的动效和清晰的布局,而且在播放时还支持内容编辑,方便我们在团队中进行高效分享和深入讨论。
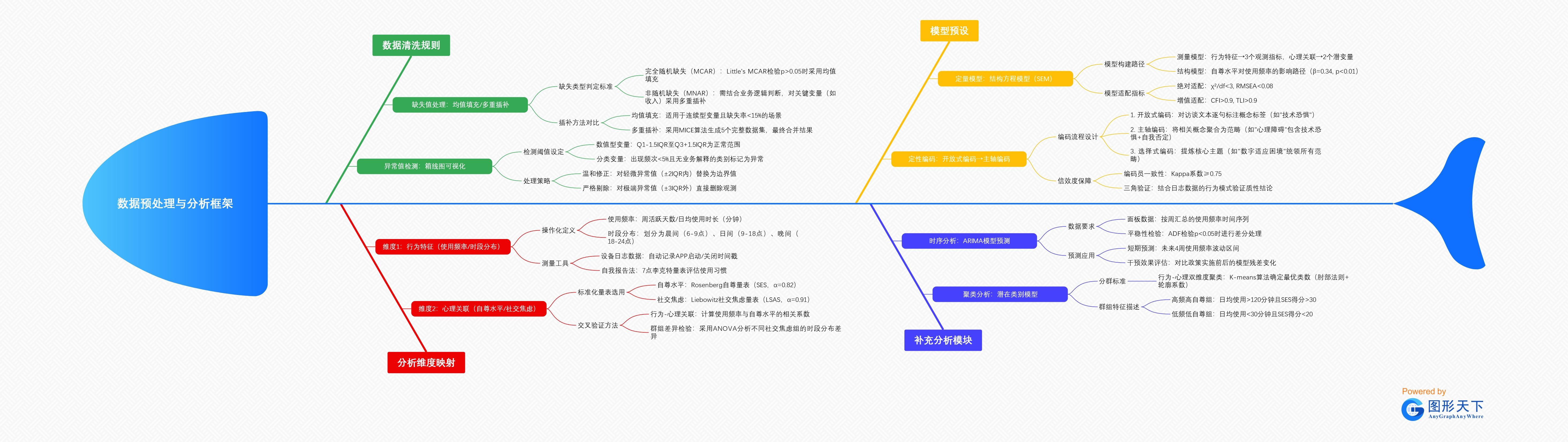
- 数据预处理与分析框架
- 数据清洗规则
- 缺失值处理:均值填充/多重插补
- 缺失类型判定标准
- 完全随机缺失(MCAR):Little’s MCAR检验p>0.05时采用均值填充
- 非随机缺失(MNAR):需结合业务逻辑判断,对关键变量(如收入)采用多重插补
- 插补方法对比
- 均值填充:适用于连续型变量且缺失率<15%的场景
- 多重插补:采用MICE算法生成5个完整数据集,最终合并结果
- 缺失类型判定标准
- 异常值检测:箱线图可视化
- 检测阈值设定
- 数值型变量:Q1-1.5IQR至Q3+1.5IQR为正常范围
- 分类变量:出现频次<5%且无业务解释的类别标记为异常
- 处理策略
- 温和修正:对轻微异常值(±2IQR内)替换为边界值
- 严格剔除:对极端异常值(±3IQR外)直接删除观测
- 检测阈值设定
- 缺失值处理:均值填充/多重插补
- 分析维度映射
- 维度1:行为特征(使用频率/时段分布)
- 操作化定义
- 使用频率:周活跃天数/日均使用时长(分钟)
- 时段分布:划分为晨间(6-9点)、日间(9-18点)、晚间(18-24点)
- 测量工具
- 设备日志数据:自动记录APP启动/关闭时间戳
- 自我报告法:7点李克特量表评估使用习惯
- 操作化定义
- 维度2:心理关联(自尊水平/社交焦虑)
- 标准化量表选用
- 自尊水平:Rosenberg自尊量表(SES,α=0.82)
- 社交焦虑:Liebowitz社交焦虑量表(LSAS,α=0.91)
- 交叉验证方法
- 行为-心理关联:计算使用频率与自尊水平的相关系数
- 群组差异检验:采用ANOVA分析不同社交焦虑组的时段分布差异
- 标准化量表选用
- 维度1:行为特征(使用频率/时段分布)
- 模型预设
- 定量模型:结构方程模型(SEM)
- 模型构建路径
- 测量模型:行为特征→3个观测指标,心理关联→2个潜变量
- 结构模型:自尊水平对使用频率的影响路径(β=0.34, p<0.01)
- 模型适配指标
- 绝对适配:χ²/df<3, RMSEA<0.08
- 增值适配:CFI>0.9, TLI>0.9
- 模型构建路径
- 定性编码:开放式编码→主轴编码
- 编码流程设计
-
- 开放式编码:对访谈文本逐句标注概念标签(如"技术恐惧")
-
- 主轴编码:将相关概念聚合为范畴(如"心理障碍"包含技术恐惧+自我否定)
-
- 选择式编码:提炼核心主题(如"数字适应困境"统领所有范畴)
-
- 信效度保障
- 编码员一致性:Kappa系数≥0.75
- 三角验证:结合日志数据的行为模式验证质性结论
- 编码流程设计
- 定量模型:结构方程模型(SEM)
- 补充分析模块
- 时序分析:ARIMA模型预测
- 数据要求
- 面板数据:按周汇总的使用频率时间序列
- 平稳性检验:ADF检验p<0.05时进行差分处理
- 预测应用
- 短期预测:未来4周使用频率波动区间
- 干预效果评估:对比政策实施前后的模型残差变化
- 数据要求
- 聚类分析:潜在类别模型
- 分群标准
- 行为-心理双维度聚类:K-means算法确定最优类数(肘部法则+轮廓系数)
- 群组特征描述
- 高频高自尊组:日均使用>120分钟且SES得分>30
- 低频低自尊组:日均使用<30分钟且SES得分<20
- 分群标准
- 时序分析:ARIMA模型预测
- 数据清洗规则

